AI for Enterprise
Bridging the Industry & Academia Gap
We help organizations cut through the noise around AI and find where it actually moves the needle, automating repetitive decisions, surfacing hidden insights, and freeing teams to focus on work that needs human judgment. We build a shared language around the technology so it stops feeling distant and starts acting like a reliable tool that sharpens operations and opens new avenues for growth.
From that foundation, we Architect enterprise-grade intelligence layers far beyond any single model or prototype. We orchestrate Graph-RAG pipelines, Multi-model mesh architectures, and Agentic workflows inside identity-bound environments, balancing accuracy, latency, and cost across hybrid and edge-native deployments. The result is an enterprise that does not just adopt AI, but becomes an adaptive system that continuously senses, decides, and rewires its core value streams.




Enterprise AI Maturity Model
Five stages. Six pillars.

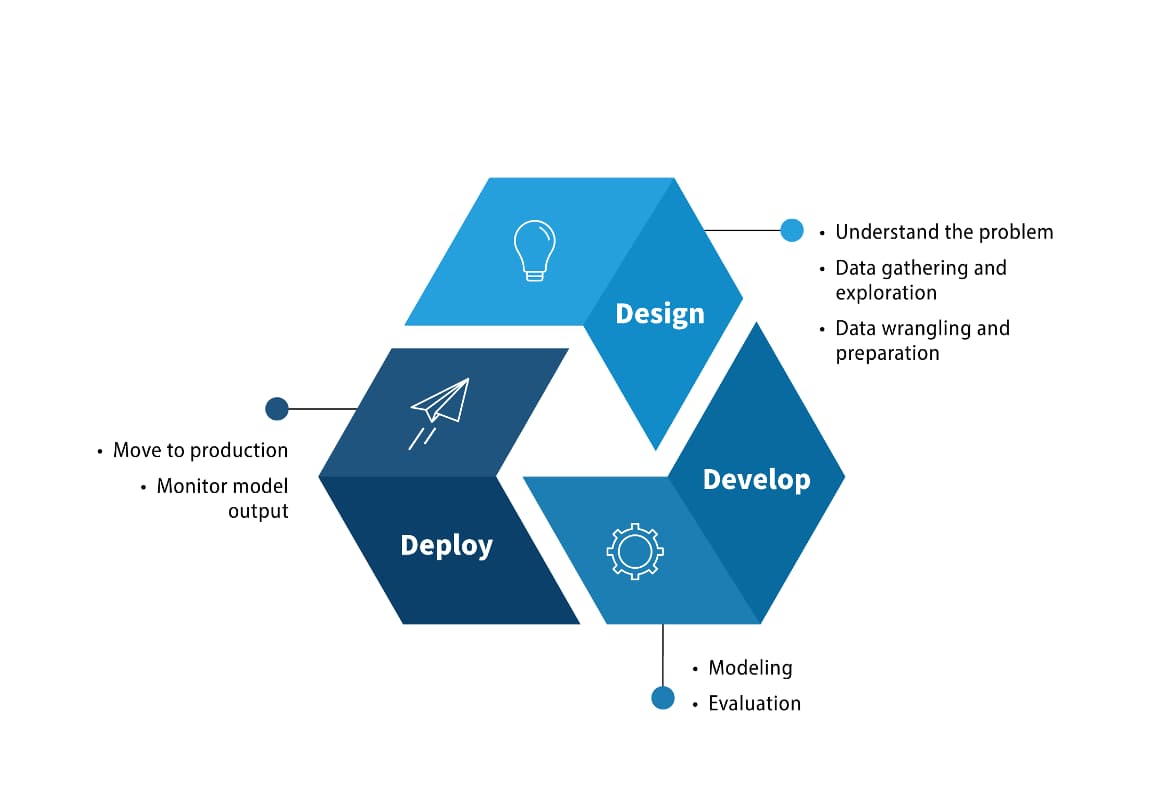
The New Productivity Paradox
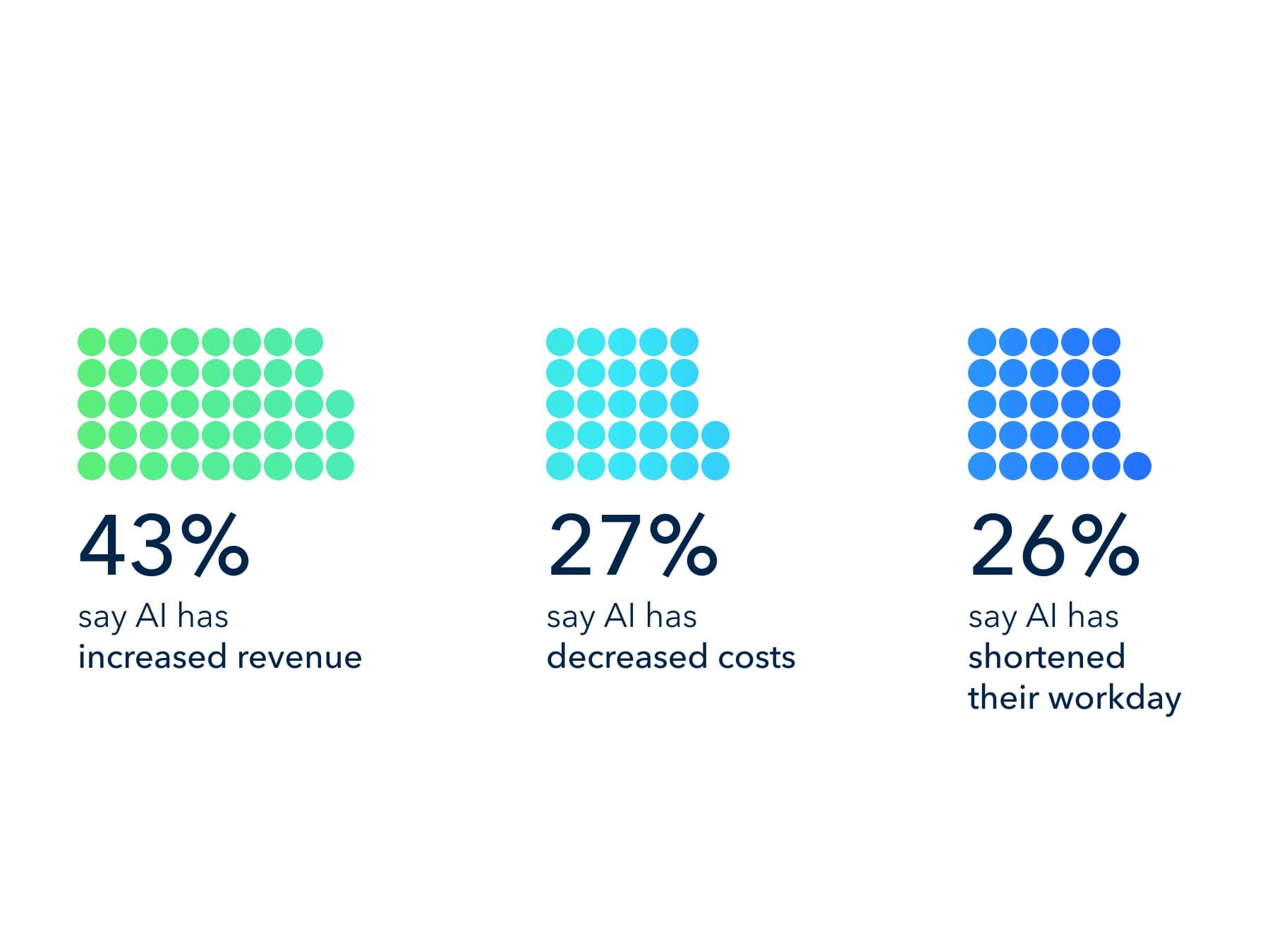
88% of enterprises have deployed AI in at least one business function. 94% report no significant value from those investments.
Robert Solow observed in 1987 that "you can see the computer age everywhere but in the productivity statistics." That paradox has returned with AI at its centre. By the end of 2025, almost nine in ten companies had deployed AI across their operations, yet the overwhelming majority of executives report that investment has not moved the needle on profitability, efficiency, or competitive position. The pattern is consistent enough to have a name: AI Theater, the performance of adoption without the structural rewiring that produces enterprise value. Procurement decisions are made. Pilots are launched. Press releases go out. The operating model stays the same.
The failure is visible in the funnel. Of the tens of billions committed to enterprise AI over the past three years, the vast majority generated no measurable return at the P&L level. Enterprise-grade, task-specific systems show a brutal attrition rate: the majority are evaluated, a fraction reach pilot stage, and only a small minority ever reach production. Most leadership teams are not aware they are operating inside this funnel. They feel progress because individual productivity is rising at the margins. Finance teams see nothing move because the underlying operating model, the processes, the incentive structures, the decision-making architecture, has not changed.
The root cause is not the algorithm. It is never the algorithm. The failure lives in the 70%: the people, process, and organisational change dimension that determines whether a capable model becomes a reliable business system. Standard consulting engagements treat this dimension as a final chapter, a change management addendum to a technology delivery project. At Power Consultancy, it is the primary workstream from day one. Technology serves the transformation. The transformation does not chase the technology.
Bridging the Industry and Academia Gap
The knowledge that matters most is trapped on either side of a wall neither party knows how to cross.
The foundational architectures of modern AI, the transformer, the attention mechanism, the principles of reinforcement learning from human feedback, emerged from academic laboratories operating under public mandates and open publication norms. But the data, compute, and talent now required to advance and deploy these systems have migrated decisively to private firms. Corporate AI research is increasingly kept internal, concentrated on pre-deployment performance, and tightly integrated with product velocity, while deployment-stage questions about model bias, distributional shift, production reliability, and long-term organisational fit go under-studied because they carry no immediate competitive advantage. The consequence is a dangerous asymmetry: industry pushes capability at scale and optimises ruthlessly for speed, while academia asks the hard questions about consequence and reliability that actually determine whether a system holds up in the real world. Power Consultancy was founded to close that gap. We operate at the intersection of both worlds by design, bringing research-grade rigour into commercial engagements and translating frontier academic methodology into the kind of industrial evidence that justifies capital commitment.
Without a bridge between these two cultures, enterprise AI optimises the wrong things extraordinarily fast. The result is systems that perform brilliantly in controlled evaluation conditions and collapse under the noise, edge cases, adversarial inputs, and organisational friction of real operations. The test distribution is never the deployment distribution. This is not a model problem. It is a process problem, and it is the problem that most technology vendors have no incentive to solve because their business model ends at delivery, not at sustained performance. The gap between what academic research understands about AI failure modes and what practitioners actually build into production systems is where the majority of enterprise AI value is currently being destroyed.
In practice, our engagements are structured around closing this gap at every stage of delivery. During diagnosis, we apply causal inference methodology drawn from clinical research to distinguish genuine signal from spurious correlation in client data before any modelling begins. During architecture, we use ontology design principles from knowledge engineering to structure domain knowledge in ways that make models genuinely interpretable to domain experts, not just technically explainable on paper. During validation, we run adversarial testing protocols modelled on academic red-teaming practices, not vendor acceptance criteria. And during production, we instrument drift monitoring with the statistical rigour of controlled experiments, with defined thresholds, documented assumptions, and retraining triggers that are evidence-based rather than calendar-based. This is what it means to bring the academy into the engine room.
Prioritisation as a Scientific Discipline
Most enterprises sequence AI investments by enthusiasm. The organisations that generate durable value sequence by value architecture.
The finding that most consistently separates high-performing AI organisations from the rest is not the sophistication of their models. It is the discipline of their investment sequencing. Organisations that generate durable value from AI share one structural trait: their initiatives are governed by measurable hypotheses tied to P&L outcomes, not by enthusiasm for particular technologies or pressure to match a competitor's announcement. The difference between a portfolio that compounds and a portfolio that fragments is almost entirely a function of how the first three use cases are chosen and in what order they are delivered.
Our prioritisation methodology evaluates every potential AI initiative across four axes: P&L materiality (what does this move and by how much, with a named baseline and a target), data infrastructure readiness (can the underlying systems actually support this at the required quality and latency), implementation complexity including the organisational change burden, and strategic compoundability (does this use case create the infrastructure, the trust, and the institutional capability required for the next one). High-impact, high-feasibility cases move immediately to Phase 1 engineering. High-impact, low-feasibility cases enter a structured research pipeline with defined de-risking milestones and a clear gate before capital scales. Low-impact cases receive no resources regardless of executive sponsorship, because the opportunity cost of misallocated attention is the single most consistent reason AI programmes stall before they matter.
The compounding logic is the dimension most organisations miss. A well-deployed demand forecasting model does not just produce forecasts. It creates the MLOps infrastructure, the data lineage practices, and the model monitoring discipline that make the next use case, whether simulation, autonomous reordering, or dynamic pricing, deployable in a fraction of the time and at a fraction of the risk. Sequence is strategy. The organisations pulling ahead of their peers are not deploying more AI use cases. They are deploying fewer, better-chosen ones, in an order that builds institutional capability with each successive delivery rather than dissipating it across competing pilots.
The Valley of Death and the FEED Methodology
67% of enterprise AI projects die between TRL 4 and TRL 6. This is not a technology problem. It is an evidence problem.
The Technology Readiness Level framework, originally developed by NASA and now standard in aerospace, defence, and energy, provides the most rigorous available language for understanding where AI projects fail. TRL 1 through 3 represents laboratory research: scientific principles observed, working model in a controlled environment, feasibility demonstrated. TRL 7 through 9 represents production reality: live deployment in an operational setting, proven under mission-critical conditions, fully integrated with enterprise systems. The gap between them, TRL 4 through 6, is called the Valley of Death. It is where concepts that work in controlled evaluation collapse under the noise, edge cases, adversarial inputs, and organisational friction of real operations. Models that ace benchmarks routinely fail in production because the test distribution was never the deployment distribution, and because the evaluation environment was designed to showcase capability rather than to stress-test reliability.
The Front-End Engineering and Development methodology, borrowed from aerospace and energy project finance, converts laboratory insights into industrial evidence before capital is committed at scale. Applied to AI, FEED means structured feasibility studies at TRL 3 to 4 using production-equivalent data rather than curated datasets, pilot design that replicates the actual inference environment including latency constraints, input quality variability, and concurrent user load, drift monitoring instrumented from the first deployment day with statistical process control thresholds rather than intuitive checks, and model documentation that records training data provenance, known failure modes, performance bounds under distribution shift, and the human oversight requirements that are non-negotiable at each risk level. This is how you de-risk the Valley of Death: not by moving faster through it, but by knowing exactly where the ground is before each step, and maintaining the discipline to halt advancement when the evidence does not yet support it.
Power Consultancy operates at TRL 4 through 6 as its primary zone of engagement. We do not hand off after the proof of concept. Concretely, this means we run adversarial testing suites against production-representative data distributions before any system moves to staging, engage domain practitioners to validate model outputs against their operational judgment rather than against holdout sets alone, enforce human-in-the-loop requirements at the inference layer through technical controls rather than policy statements, and instrument closed-loop monitoring with defined retraining triggers tied to measurable performance degradation thresholds. When a logistics forecasting model is deployed, we track not just accuracy but downstream operational decisions it influences and the cost of errors in each category. When a legal document processing system goes live, we monitor not just extraction precision but the rate of edge cases that require escalation and the time cost of each. TRL 7 is earned through this kind of evidence, not declared through optimism at the end of a sprint.
Agentic Infrastructure and Sovereign Architecture
The next frontier is not better models. It is trustworthy infrastructure that can govern autonomous systems operating at enterprise scale.
Agentic AI, systems that plan, reason, and execute multi-step workflows without human initiation, is moving from experimental framing to production deployment faster than enterprise governance models can absorb. The capability is genuinely transformative: agents can read databases, call internal APIs, file procurement tickets, send emails, draft contracts, and execute code, all within a single orchestrated workflow and without a human in the loop at each step. The operational upside is significant. The governance gap is larger. The majority of enterprises now running agentic pilots have no identity layer for non-human actors, no audit trail of agent-initiated actions, and no policy fabric that defines what those agents are and are not permitted to do on behalf of the organisation. This is not a compliance risk in the abstract. It is a structural vulnerability in operations, and it compounds with every additional agent deployed.
Sovereign AI has moved from boardroom talking point to architectural requirement. The EU AI Act's phased enforcement timeline, the tightening of cross-border data regulations, and the geopolitical realities of operating sensitive AI workloads on infrastructure controlled by third-party hyperscalers have made sovereignty a board-level question rather than an IT preference. Sovereignty, properly understood, is not a hosting location. It is a design principle with three measurable properties: architectural control, meaning the ability to run every component of the system locally with no external dependencies if required; data jurisdiction, meaning data does not leave a defined perimeter without explicit consent and an auditable record; and compliance portability, meaning the evidence of regulatory conformance travels with workloads across cloud, on-premise, and air-gapped environments without requiring manual reconstruction at each audit.
Our infrastructure philosophy is built on open-source model foundations, customer-held encryption keys, air-gap capable deployment architecture, and fully auditable data and model lineage from the first sprint. In practice this means we select open-weight foundation models that can be fine-tuned and served entirely within a client's own infrastructure, with no inference calls to external APIs and no training data leaving the client's control boundary. Every agent receives its own non-human identity with least-privilege access, policies enforced at the gateway layer rather than assumed through role definitions, and a complete action log with tamper-evident provenance. Every deployed model carries a card that documents its training data sources, the known failure modes identified during validation, performance bounds under distribution shift, and the conditions under which human review is mandatory. Governance is a design constraint from the first architectural decision, not a retrofit applied before the compliance audit.
Executive Enablement and Organisational Rewiring
The technology is not the constraint. The leadership operating model is.
When AI use becomes pervasive across an industry, it ceases to confer competitive advantage on any individual organisation within it. The capability becomes table stakes. The differentiation shifts to what the technology cannot replicate: the judgment to ask the right questions of systems that leaders do not fully understand, the creativity to identify the problems worth solving before competitors frame them, the institutional courage to act on ambiguous signals before the evidence is comfortable, and the cross-disciplinary fluency to translate between technical possibility and operational reality. In an AI-saturated environment, the scarcest enterprise asset is not a better model. It is a leadership team that is genuinely equipped to govern one.
The structural challenge is that most executive development in AI stops at awareness. Leaders attend a briefing, interact with a tool, and leave with a broad sense of the technology's potential and no specific capability for applying it to the decisions they actually make. The transition from awareness to operational competence requires something different: structured engagement with real work, real data, and real decisions, not curated demonstrations. It requires redesigning the work itself around human-AI collaboration patterns rather than layering tools onto processes designed for a pre-AI operating environment. And it requires embedding accountability for AI outcomes into the leadership structures that govern P&L, risk, and talent, rather than delegating it to a centre of excellence that operates adjacent to the business rather than inside it.
Our executive enablement programme is built across four levels that compound on each other structurally. Level 1 builds personal fluency through hands-on engagement with real executive tasks: drafting strategic communications, stress-testing investment theses, reviewing complex documents, running scenario analyses. The goal is calibrated intuition, the ability to judge where AI output can be trusted and where human review is non-negotiable. Level 2 redesigns workflows by mapping where AI can eliminate decision latency, reduce information asymmetry, or absorb routine cognitive load, and then restructuring those processes around the new capability rather than leaving them unchanged and adding a tool on top. Level 3 develops team leadership capacity, the ability to set expectations, manage performance, and build a team culture in which AI is an operational expectation rather than an individual experiment. Level 4 is portfolio governance: owning the AI P&L, setting the enterprise risk appetite for autonomous systems, driving the cross-functional alignment that determines whether the organisation's AI investments compound or fragment. Each level is measured against operational outcomes rather than completion. The programme ends when the capability is demonstrated in practice, not when the curriculum is finished.
The Governance Imperative
Governance is not compliance overhead. It is the prerequisite for trust at scale, and the infrastructure that makes AI deployment repeatable.
The number of documented AI failures in production environments has risen sharply every year since 2022, and the trajectory reflects a structural problem rather than growing pains. As AI systems take on more consequential decisions across more operational domains, the surface area for failure expands faster than most organisations' ability to monitor, contain, and remediate it. The gap between recognising AI risk and acting on it architecturally defines the governance crisis facing enterprise AI today. The EU AI Act has converted this from an ethical conversation into an enforceable financial one. Prohibited practices, including subliminal manipulation, social scoring, and untargeted biometric data scraping, have been banned since February 2025. General-purpose AI governance structures were required from August 2025. Full obligations for high-risk AI systems, those operating in employment, credit, critical infrastructure, and education, apply from August 2026, with penalties reaching 35 million euros or 7% of global annual turnover.
Risk is not binary, and treating it as such is itself a governance failure. Our framework classifies every AI use case across four tiers with corresponding obligations calibrated to actual consequence. Prohibited systems are identified and excluded before a line of code is written. High-risk systems, those making or materially informing decisions with significant impact on individuals, require conformity assessments, traceability logging to Article 12 standards, human oversight mechanisms that are technically enforced rather than policy-stated, and a designated executive with named, documented accountability for the system's lifecycle. Limited-risk systems require transparency disclosures. Minimal-risk applications are monitored but not over-governed. The calibration matters: over-governing minimal-risk systems creates the compliance overhead that slows organisations down and diverts attention from the cases where governance actually prevents harm. Under-governing high-risk systems creates the incidents that destroy institutional trust and trigger regulatory intervention.
The governance architecture we build for every client is specific and operational, not aspirational. Every deployed system carries a model card that records training data provenance, validation methodology, known failure modes, performance bounds under distribution shift, and the conditions under which human review is mandatory. Post-market monitoring plans are active from the first day of production, not drafted as a deliverable at the end of the engagement. Drift detection is instrumented with statistical process control thresholds, not intuitive checks. Incident escalation procedures are mapped to regulatory frameworks with clear ownership at each step. Audit trails are structured to travel with workloads across cloud, on-premise, and air-gapped environments, so that compliance evidence is available without manual reconstruction at each review. And retraining protocols are evidence-based: triggered by measured performance degradation against defined thresholds, not by calendar schedules or engineering intuition. This is what governance looks like when it is built to function rather than built to satisfy a checklist.
Most AI Engagements Begin with a Pitch. Ours Begins with a Diagnosis.
If your organisation is investing in AI without a clear line from deployment to P&L impact, we would like to understand why, and show you what the path forward looks like. No deck. No generic roadmap. A structured diagnostic of where you are on the maturity curve, where the value is, and what is standing between you and it.
Get in TouchTypically a two-hour structured session with your leadership team. No commercial obligation.