L1
L6
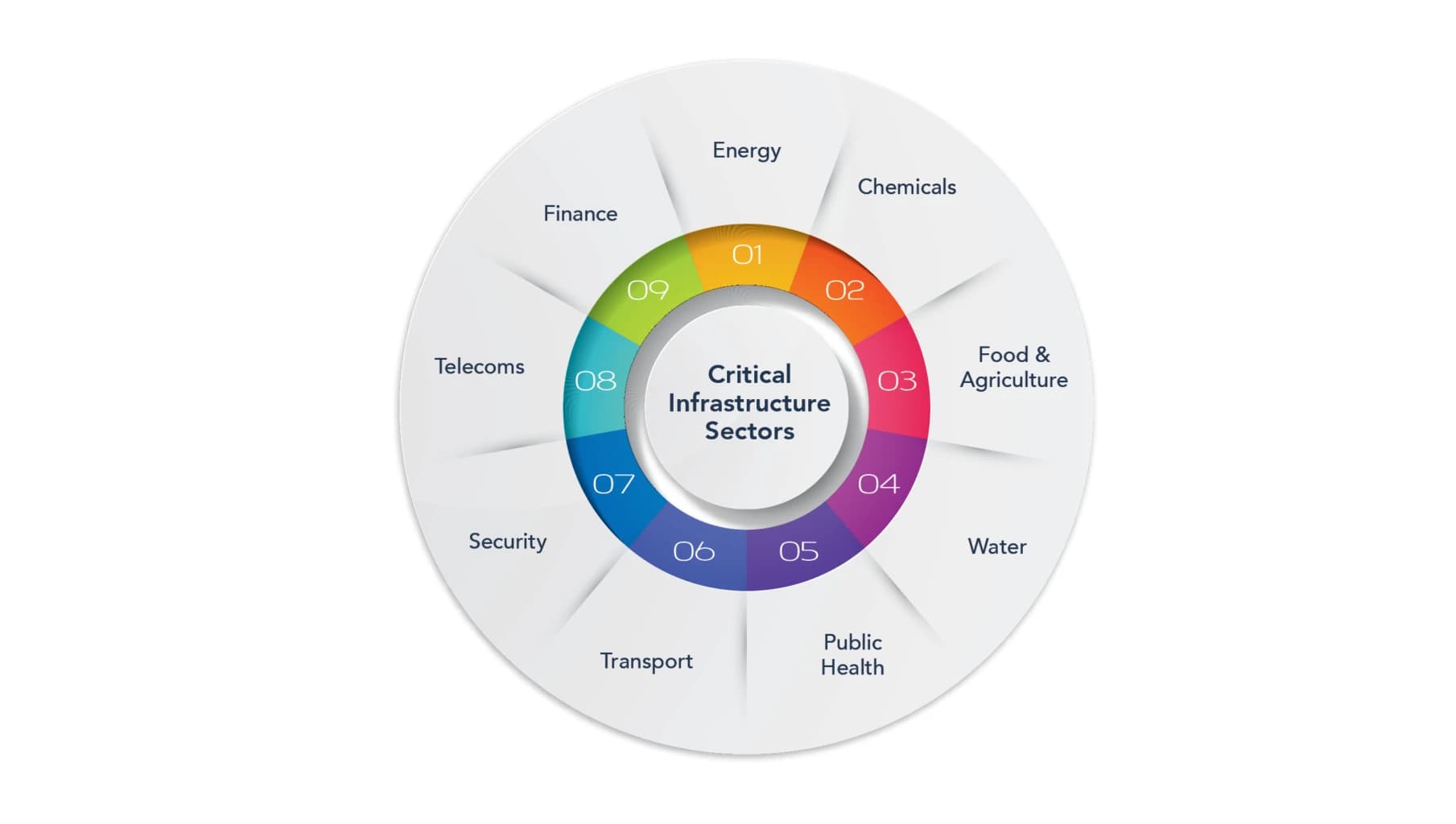
Index
Architecture Key
›
Layer numbers denote function. The signal shows sequence.
L6
Governance
Observability
Audit trail begins. Query logged, timestamped, immutable.
Incoming query received
Audit entry created · ID: q-8f3a
Routing to orchestration layer
L3
Orchestration
Agent Network
Orchestrator decomposes the query. Spawns retrieval + reasoning agents.
Query intent classified
Agent: retrieval-agent-01 spawned
Agent: validator-agent-01 spawned
Handoff protocol initiated
L2
Integration
MCP Layer
Agents reach into enterprise systems. Every tool call permissioned and logged.
Connector: doc-mgmt-system
Connector: regulatory-db
14 documents retrieved
Access logged · no boundary crossed
L4
Semantics
Knowledge Graph
Retrieved data grounded in your domain ontology. Consistency enforced.
Entities mapped to ontology
3 semantic paths resolved
No contradictions detected
Reasoning trace constructed
L1
Inference
Foundation Model
Fine-tuned model reasons over grounded evidence. No external API. No token fees.
Domain model: legal-llm-v3
Context: 4,218 tokens
Generating response...
Confidence: 0.94
L5
Infrastructure
Sovereign Deployment
Every computation runs inside your perimeter. Zero external exposure.
Running on: on-prem cluster 03
Jurisdiction: confirmed ✓
External egress: none
Encryption keys: customer-held
// incoming query
"Summarise the regulatory obligations for our new contract under Directive 2024/38/EU, flagging any gaps against our current compliance framework."
// layer status
Governance L6 · Observability
idle
Orchestration L3 · Agent Network
idle
Integration L2 · MCP Layer
idle
Semantics L4 · Knowledge Graph
idle
Inference L1 · Foundation Model
idle
Infrastructure L5 · Sovereign Deployment
idle
// output
Awaiting query execution...